Creating a Basic Web Scraper With Python 🐍
Learn How to Scrape Indeed.com

I recently got into web scraping as a way to simplify database insertion for a side project of mine. The uses of web scrapers are endless. You can create a web scraper to collect different football stats, download videos or images, compare flight prices, and more. Whatever you do, just keep in mind there are some basic legal restrictions on scrapers that I won't get into, but that you can read more about here.
For this tutorial, we are going to scrape the Indeed website for relevant software developer jobs. There are two main tools to choose from for scraping with Python: BeautifulSoup and Selenium. While BeautifulSoup will work with the Indeed website, we are going to use Selenium because Selenium works on JavaScript heavy websites (most modern websites that use frameworks). In other words, you'll be able to use it more.
This tutorial works with Indeed's layout as of 11/15/21. Websites change all the time, but hopefully this tutorial will give you enough guidance to make any updates as needed.
Installation & Imports
Begin by installing Selenium. For more information visit the Selenium website .
pip install selenium
Import the following into your Python file:
import time
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import NoSuchElementException
Grabbing The Job Posts
Now, we will create function that visits the Indeed website and gathers the company name, position, description, link, and salary from each job positing on the page. That function will also be adding each posting to a list of dictionaries. Let's start with having webdriver visit the page:
def find_jobs():
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://www.indeed.com/jobs?q=software%20developer&l=remote&vjk=1e9c69b0185f6d30')
# Searching for software developer positions that are remote.
# Change this as you wish or convert it to accept input variables
Scraping is primarily about finding HTML elements and gather data from them. Inspect the page. What do you notice about the page's layout in your dev tools? I noticed that each posting was contained in an a tag with a class of tapItem.
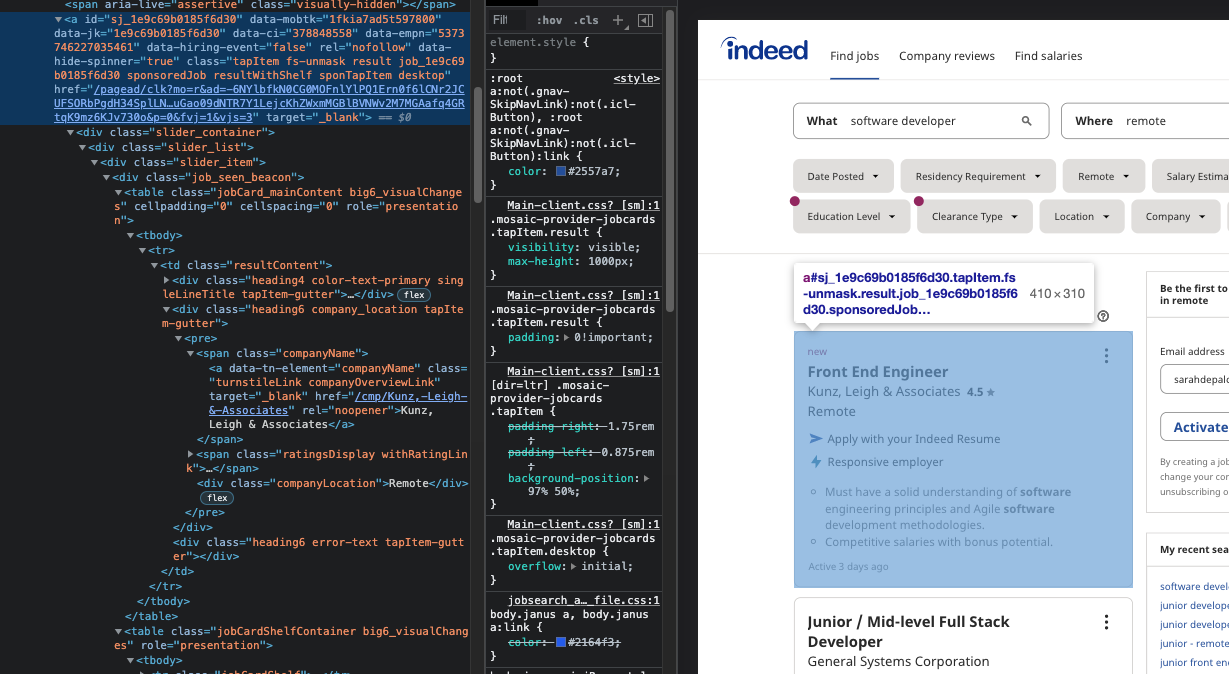
To create a list of items use driver.find_elements_by_class_name('tapItem'). Check out the full list of selectors at the Selenium website .
jobs = driver.find_elements_by_class_name('tapItem')
job_list = []
#This will hold all of the dictionaries we create for each item.
Finding The Job Information
We are going to loop through each of those jobs and find their corresponding title, company and more. With your dev tools still open, can you locate the HTML tag that holds the company name? How about the location? Once you locate them, select them using the selector above (or a different you found in the Selenium docs).
for j in jobs:
dictionary = {}
company = j.find_element_by_class_name('companyName').text
dictionary['company'] = company
position = j.find_element_by_class_name('jobTitle').text
dictionary['position'] = position
location = j.find_element_by_class_name('companyLocation').text
dictionary['location'] = location
You may have noticed that some job postings list the salary while others do not. Salary information is still very important so how can we grab those that list it? The answer is to use a try catch.
try:
salary = j.find_element_by_class_name('salary-snippet-container')
dictionary['salary'] = salary.text
except NoSuchElementException:
dictionary['salary'] = 'No salary listed'
All that's left to collect is a link to more information and a short description. Let's grab those!
description = j.find_element_by_class_name('job-snippet').text
dictionary['description'] = description
Finding the link to view more information is actually really easy for this project. Remember how we selected that a tag earlier? We just have to select the href of that tag and we're all set!
dictionary['link'] = j.get_attribute('href')
Creating .txt Files For Each Posting
Alright, we have all of the information, but reading the postings in your terminal isn't very fun or practical. Instead, we are going to create a .txt document with the information we've gathered. We are also going to run our get_jobs function every 15 minutes so we can get the newest job postings without doing anything! Let's append those dictionaries to our list and save those files! Create a folder called jobPosts to store the txt files.
job_list.append(dictionary)
with open(f'jobPosts/{company.replace(" ", "")}.txt', 'w') as f:
f.write(f"{company}\n {position}\n {location}\n {dictionary['salary']} \n {description} \n {dictionary['link']}")
print(f'File saved: {company.replace(" ", "")}.txt')
To run the script every 15 minutes, add this to the end of your code outside of the find_jobs function:
if __name__ == '__main__':
while True:
find_jobs()
time_wait = 15
print(f'Waiting {time_wait} minutes...')
time.sleep(time_wait * 60)
Congratulations, you've made your first scraper! Now you can run your scraper and have new jobs in this folder every 15 minutes! Sweet! 🍻
This is just one example of how you can automate your life with Python and web scraping. If you used this tutorial let me know what else you've created or want to create with Python! Thanks for reading! ✨✨
Full Code
import time
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import NoSuchElementException
def find_jobs():
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://www.indeed.com/jobs?q=software%20developer&l=remote&vjk=1e9c69b0185f6d30')
jobs = driver.find_elements_by_class_name('tapItem')
job_list = []
for j in jobs:
dictionary = {}
company = j.find_element_by_class_name('companyName').text
dictionary['company'] = company
position = j.find_element_by_class_name('jobTitle').text
dictionary['position'] = position
location = j.find_element_by_class_name('companyLocation').text
dictionary['location'] = location
try:
salary = j.find_element_by_class_name('salary-snippet-container')
dictionary['salary'] = salary.text
except NoSuchElementException:
dictionary['salary'] = 'No salary listed'
description = j.find_element_by_class_name('job-snippet').text
dictionary['description'] = description
dictionary['link'] = j.get_attribute('href')
job_list.append(dictionary)
with open(f'jobPosts/{company.replace(" ", "")}.txt', 'w') as f:
f.write(f"{company}\n {position}\n {location}\n {dictionary['salary']} \n {description} \n {dictionary['link']}")
print(f'File saved: {company.replace(" ", "")}.txt')
if __name__ == '__main__':
while True:
find_jobs()
time_wait = 15
print(f'Waiting {time_wait} minutes...')
time.sleep(time_wait * 60)




